Lab Meeting on 22 August 2019
There were SO many great questions and conversations at this week’s lab meeting that we ran over time and ended up chatting for more than 2 hours.
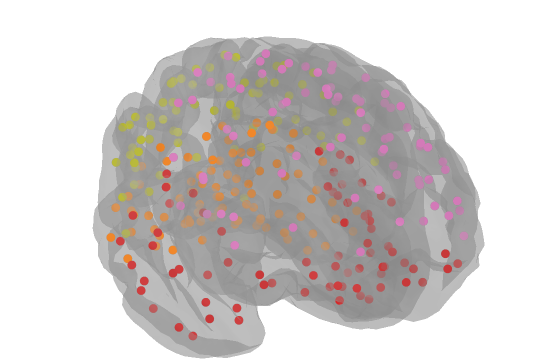
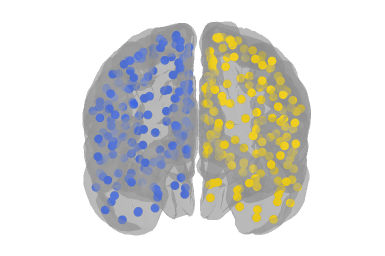
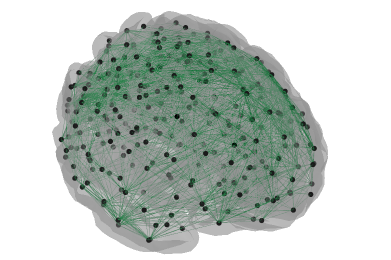
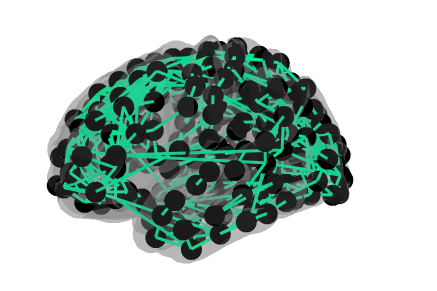
There are lots of updates here, and some really fascinating questions that we didn’t manage to answer, but please do scroll to the end to see a few of Ruslan Yermakov’s excellent brain visualisations for the scona🍪 (Structural Covariance Network Analyses) project (https://github.com/WhitakerLab/scona).
Celebrations and cool things to share
Patricia is starting a new job in September and her new team is running a survey on FAIR data policies and practices. It would be great for everyone to complete it and share widely!
Maxine is back on track with thesis writing after a rough few weeks of re-running all of her analyses because there was a mistake at the very start 😱 This week she’s writing new analyses (rather than re-writing the chapters that had to be updated). Kirstie is wildly proud that a whole PhD can be re-run in just a few weeks! Reproducible research FTW ✨ 🙌 🚀 😻
In contrast, Josh has been busy incorporating feedback for his thesis proposal. He also took a break from his PhD by writing a blog on Four things I wish I’d known before starting a PhD. (With the excellent subtitle: Some Of Which I Probably Could Have Guessed And Most Of Which I Was Probably Told At Some Point, But Now Know For Sure.)
Sarah is much more organised with her post-it to-do list method 💖
Christina is working on a fascinating project thinking about the ethics of machine learning in children’s social care. Good luck with the tight deadline Christina!!
Louise shared a new colourmap from Google: Turbo: An improved rainbow colormap for visualisation. The linked blog is great discussion of the pros and cons of rainbow colourmaps 🌈
Yini is “Learning Python the Hard Way” (via the book by Zed A Shaw recommended by Sarah and Georgia. She found this video on youtube really helpful: https://www.youtube.com/watch?v=9k8s8r5DXNU.
Yini also recommended the “Tell me a story” point of view article by Joshua Sanes at eLife (doi: 10.7554/eLife.50527). Sanes suggests starting with the introduction and results sections of a paper and leaving the figures to later.
(Side note: This is not Kirstie’s style at all, she’s super into figures to tell the story, but its worth reading and seeing what fits your workflow best!)
Malvika is enjoying getting to know The Turing Way better, and would love to hear about your contributions and ideas for the project.
Ang is really happy to get a revise and resubmit re-consideration by the editor for his first first author paper. Fingers crossed 🤞 🤞
Yo is having tonnes of fun interviewing participants for her PhD research study. About 10 hours so far, and at least as much more over the next few weeks. She’s feeling happy and excited that people are so ready and willing to help 💖 Good luck on all the transcriptions Yo!
Yo also shared http://citeas.org as a really useful page to know how to cite something (dois, urls and arXiv ids all included).
Elizabeth was sad to miss Fernando Perez’s live stream at the American National Science Foundation last week, but recommends going through the 🌟 amazing 🌟 slides:
Georgia is excited that we have some of our first contributions to the citizen science project from our survey and mailing list ✨
Questions we’re thinking about
Sarah asked “What are the lab’s tips for keeping your energy/interest going through a conference?”
We recommended taking breaks and feeling ok with skipping some sessions. A tired researcher sitting at the back of a hot conference hall isn’t learning anything, and if you’re fresh then you’re able to be present and focus on the talks.
Patricia asked for the group’s recommendations on keeping desktops (in physical and virtual space) decluttered? How do you make time for that in your calendar? Every 6 months?
Yini pointed out that it helps that the Turing only has hot desks so you have to tidy up every evening 😕
Christina is learning about different types of machine learning - supervised, unsupervised, semi-supervised or reinforcement - and the different ways they can be applied. Specifically she’s interested in thinking about the ethical considerations that differ across the different types of analyses. She’s had lots of useful conversations at the Turing, and we had some great discussion at the end of lab meeting. This is going to be an awesome paper that she’s currently writing!
Georgia is working out comms strategies for the citizen science project. She’d love suggestions how to engage and involve people?
Elizabeth is brainstorming what an ideal Jupyter “authoring experience” could look like. She’d love comments on this initial sketch of a workflow!
Ang wonders if there’s a better way to test the heterogeneity of one-dimensional continuous data across two groups? The goal is to test whether one measurement is more heterogeneous than another (instead of, for example, performing an F-test, which comparing the variance of two distributions).
Yo is wondering about tips for applying for research fellowships?
Anything else
We didn’t answer many of our own questions, because Google Summer of Code student Ruslan Yermakov joined us to present his work on scona🍪.
You can read his final report and check out the fantastic tutorials he made in Binder:
Here are a few lovely images to close out the blog.